|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| |
| Phenotypic Information (metabolism pathway, cancer, disease, phenome) |
| |
| |
| Gene-Gene Network Information: Co-Expression Network, Interacting Genes & KEGG |
| |
|






| Gene Summary for PRODH |
| Basic gene info. | Gene symbol | PRODH |
| Gene name | proline dehydrogenase (oxidase) 1 | |
| Synonyms | HSPOX2|PIG6|POX|PRODH1|PRODH2|TP53I6 | |
| Cytomap | UCSC genome browser: 22q11.21 | |
| Genomic location | chr22 :18900286-18924066 | |
| Type of gene | protein-coding | |
| RefGenes | NM_001195226.1, NM_016335.4, | |
| Ensembl id | ENSG00000100033 | |
| Description | p53-induced gene 6 proteinproline dehydrogenase 1, mitochondrialproline oxidase 2proline oxidase, mitochondrialtumor protein p53 inducible protein 6 | |
| Modification date | 20141211 | |
| dbXrefs | MIM : 606810 | |
| HGNC : HGNC | ||
| Ensembl : ENSG00000100033 | ||
| HPRD : 08433 | ||
| Vega : OTTHUMG00000150163 | ||
| Protein | UniProt: O43272 go to UniProt's Cross Reference DB Table | |
| Expression | CleanEX: HS_PRODH | |
| BioGPS: 5625 | ||
| Gene Expression Atlas: ENSG00000100033 | ||
| The Human Protein Atlas: ENSG00000100033 | ||
| Pathway | NCI Pathway Interaction Database: PRODH | |
| KEGG: PRODH | ||
| REACTOME: PRODH | ||
| ConsensusPathDB | ||
| Pathway Commons: PRODH | ||
| Metabolism | MetaCyc: PRODH | |
| HUMANCyc: PRODH | ||
| Regulation | Ensembl's Regulation: ENSG00000100033 | |
| miRBase: chr22 :18,900,286-18,924,066 | ||
| TargetScan: NM_001195226 | ||
| cisRED: ENSG00000100033 | ||
| Context | iHOP: PRODH | |
| cancer metabolism search in PubMed: PRODH | ||
| UCL Cancer Institute: PRODH | ||
| Assigned class in ccmGDB | A - This gene has a literature evidence and it belongs to cancer gene. | |
| References showing role of PRODH in cancer cell metabolism | 1. Liu W, Le A, Hancock C, Lane AN, Dang CV, et al. (2012) Reprogramming of proline and glutamine metabolism contributes to the proliferative and metabolic responses regulated by oncogenic transcription factor c-MYC. Proceedings of the National Academy of Sciences 109: 8983-8988. go to article | |
| Top |
| Phenotypic Information for PRODH(metabolism pathway, cancer, disease, phenome) |
| Cancer | CGAP: PRODH |
| Familial Cancer Database: PRODH | |
| * This gene is included in those cancer gene databases. |
|
|
|
|
|
| . | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Oncogene 1 | Significant driver gene in | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| cf) number; DB name 1 Oncogene; http://nar.oxfordjournals.org/content/35/suppl_1/D721.long, 2 Tumor Suppressor gene; https://bioinfo.uth.edu/TSGene/, 3 Cancer Gene Census; http://www.nature.com/nrc/journal/v4/n3/abs/nrc1299.html, 4 CancerGenes; http://nar.oxfordjournals.org/content/35/suppl_1/D721.long, 5 Network of Cancer Gene; http://ncg.kcl.ac.uk/index.php, 1Therapeutic Vulnerabilities in Cancer; http://cbio.mskcc.org/cancergenomics/statius/ |
| KEGG_ARGININE_AND_PROLINE_METABOLISM REACTOME_METABOLISM_OF_AMINO_ACIDS_AND_DERIVATIVES | |
| OMIM | 181500; phenotype. 181500; phenotype. 239500; phenotype. 239500; phenotype. 600850; phenotype. 600850; phenotype. 606810; gene. 606810; gene. |
| Orphanet | 3140; Schizophrenia. 3140; Schizophrenia. 419; Hyperprolinemia type 1. 419; Hyperprolinemia type 1. |
| Disease | KEGG Disease: PRODH |
| MedGen: PRODH (Human Medical Genetics with Condition) | |
| ClinVar: PRODH | |
| Phenotype | MGI: PRODH (International Mouse Phenotyping Consortium) |
| PhenomicDB: PRODH | |
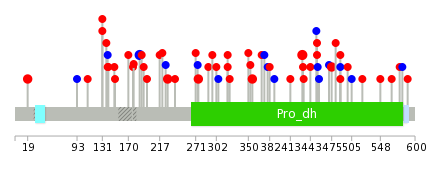
| Mutations for PRODH |
| * Under tables are showing count per each tissue to give us broad intuition about tissue specific mutation patterns.You can go to the detailed page for each mutation database's web site. |
| There's no structural variation information in COSMIC data for this gene. |
| * From mRNA Sanger sequences, Chitars2.0 arranged chimeric transcripts. This table shows PRODH related fusion information. |
| ID | Head Gene | Tail Gene | Accession | Gene_a | qStart_a | qEnd_a | Chromosome_a | tStart_a | tEnd_a | Gene_a | qStart_a | qEnd_a | Chromosome_a | tStart_a | tEnd_a |
| AI497670 | USP11 | 22 | 287 | X | 47107462 | 47107727 | PRODH | 282 | 345 | 22 | 18913475 | 18913538 | |
| Top |
| Mutation type/ Tissue ID | brca | cns | cerv | endome | haematopo | kidn | Lintest | liver | lung | ns | ovary | pancre | prost | skin | stoma | thyro | urina | |||
| Total # sample | 2 | |||||||||||||||||||
| GAIN (# sample) | 2 | |||||||||||||||||||
| LOSS (# sample) |
| cf) Tissue ID; Tissue type (1; Breast, 2; Central_nervous_system, 3; Cervix, 4; Endometrium, 5; Haematopoietic_and_lymphoid_tissue, 6; Kidney, 7; Large_intestine, 8; Liver, 9; Lung, 10; NS, 11; Ovary, 12; Pancreas, 13; Prostate, 14; Skin, 15; Stomach, 16; Thyroid, 17; Urinary_tract) |
| Top |
|
 |
| Top |
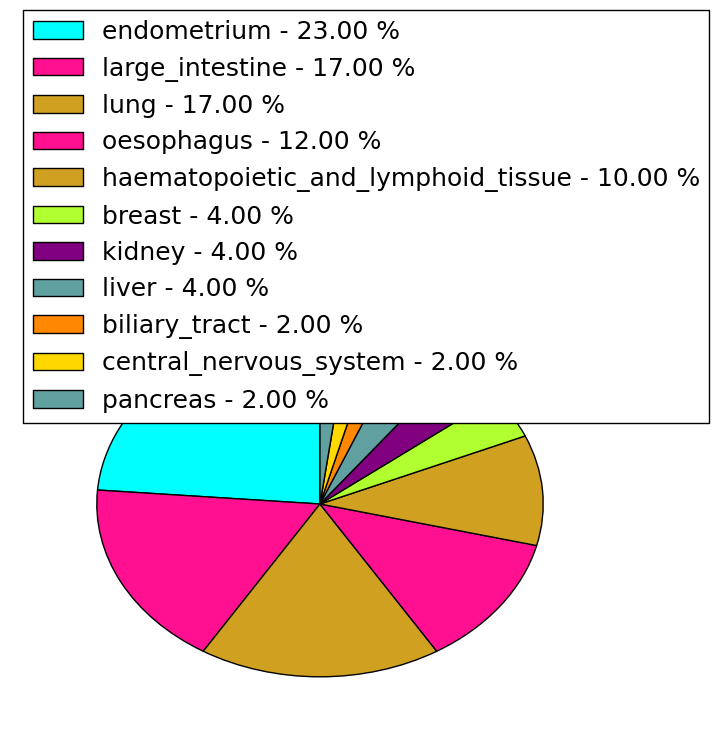
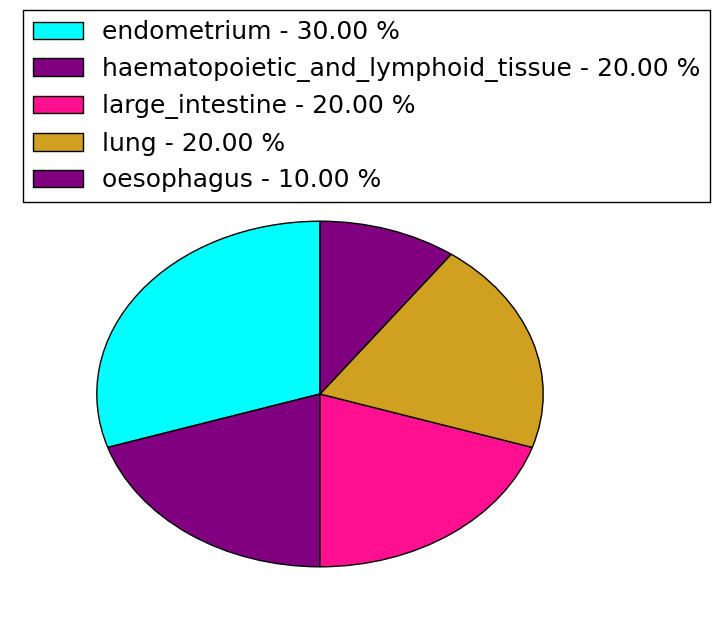
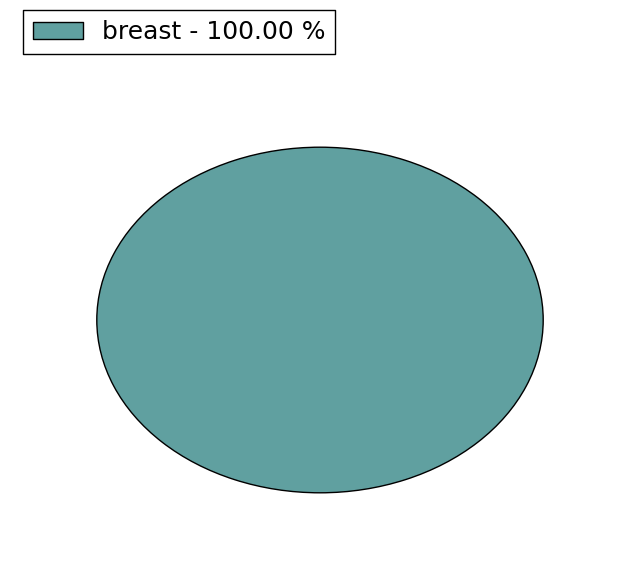
| Stat. for Non-Synonymous SNVs (# total SNVs=47) | (# total SNVs=10) |
 |  |
(# total SNVs=0) | (# total SNVs=1) |
 |
| Top |
| * When you move the cursor on each content, you can see more deailed mutation information on the Tooltip. Those are primary_site,primary_histology,mutation(aa),pubmedID. |
| GRCh37 position | Mutation(aa) | Unique sampleID count |
| chr22:18912670-18912670 | p.F187F | 3 |
| chr22:18905964-18905964 | p.R431H | 3 |
| chr22:18905833-18905833 | p.H475Y | 2 |
| chr22:18908910-18908910 | p.S319I | 2 |
| chr22:18910675-18910675 | p.G229C | 2 |
| chr22:18923745-18923745 | p.P19Q | 2 |
| chr22:18907255-18907255 | p.M356I | 2 |
| chr22:18910355-18910355 | p.T275N | 2 |
| chr22:18910641-18910641 | p.R240K | 1 |
| chr22:18912699-18912699 | p.D178N | 1 |
| Top |
|
 |
| Point Mutation/ Tissue ID | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| # sample | 3 | 1 | 4 | 1 | 1 | 2 | 1 | 4 | 1 | 4 | 10 | |||||||||
| # mutation | 3 | 1 | 4 | 1 | 1 | 2 | 1 | 4 | 1 | 4 | 14 | |||||||||
| nonsynonymous SNV | 2 | 1 | 4 | 1 | 1 | 2 | 1 | 3 | 1 | 1 | 11 | |||||||||
| synonymous SNV | 1 | 1 | 3 | 3 |
| cf) Tissue ID; Tissue type (1; BLCA[Bladder Urothelial Carcinoma], 2; BRCA[Breast invasive carcinoma], 3; CESC[Cervical squamous cell carcinoma and endocervical adenocarcinoma], 4; COAD[Colon adenocarcinoma], 5; GBM[Glioblastoma multiforme], 6; Glioma Low Grade, 7; HNSC[Head and Neck squamous cell carcinoma], 8; KICH[Kidney Chromophobe], 9; KIRC[Kidney renal clear cell carcinoma], 10; KIRP[Kidney renal papillary cell carcinoma], 11; LAML[Acute Myeloid Leukemia], 12; LUAD[Lung adenocarcinoma], 13; LUSC[Lung squamous cell carcinoma], 14; OV[Ovarian serous cystadenocarcinoma ], 15; PAAD[Pancreatic adenocarcinoma], 16; PRAD[Prostate adenocarcinoma], 17; SKCM[Skin Cutaneous Melanoma], 18:STAD[Stomach adenocarcinoma], 19:THCA[Thyroid carcinoma], 20:UCEC[Uterine Corpus Endometrial Carcinoma]) |
| Top |
| * We represented just top 10 SNVs. When you move the cursor on each content, you can see more deailed mutation information on the Tooltip. Those are primary_site, primary_histology, mutation(aa), pubmedID. |
| Genomic Position | Mutation(aa) | Unique sampleID count |
| chr22:18918708 | p.L93L | 2 |
| chr22:18905928 | p.Y440C,PRODH | 1 |
| chr22:18912582 | p.A163D,PRODH | 1 |
| chr22:18900797 | p.N391D,PRODH | 1 |
| chr22:18918658 | p.H151Y,PRODH | 1 |
| chr22:18906002 | p.N380D,PRODH | 1 |
| chr22:18912624 | p.S118S,PRODH | 1 |
| chr22:18900848 | p.V373M,PRODH | 1 |
| chr22:18906976 | p.A113T,PRODH | 1 |
| chr22:18912638 | p.H367Y,PRODH | 1 |
| * Copy number data were extracted from TCGA using R package TCGA-Assembler. The URLs of all public data files on TCGA DCC data server were gathered on Jan-05-2015. Function ProcessCNAData in TCGA-Assembler package was used to obtain gene-level copy number value which is calculated as the average copy number of the genomic region of a gene. |
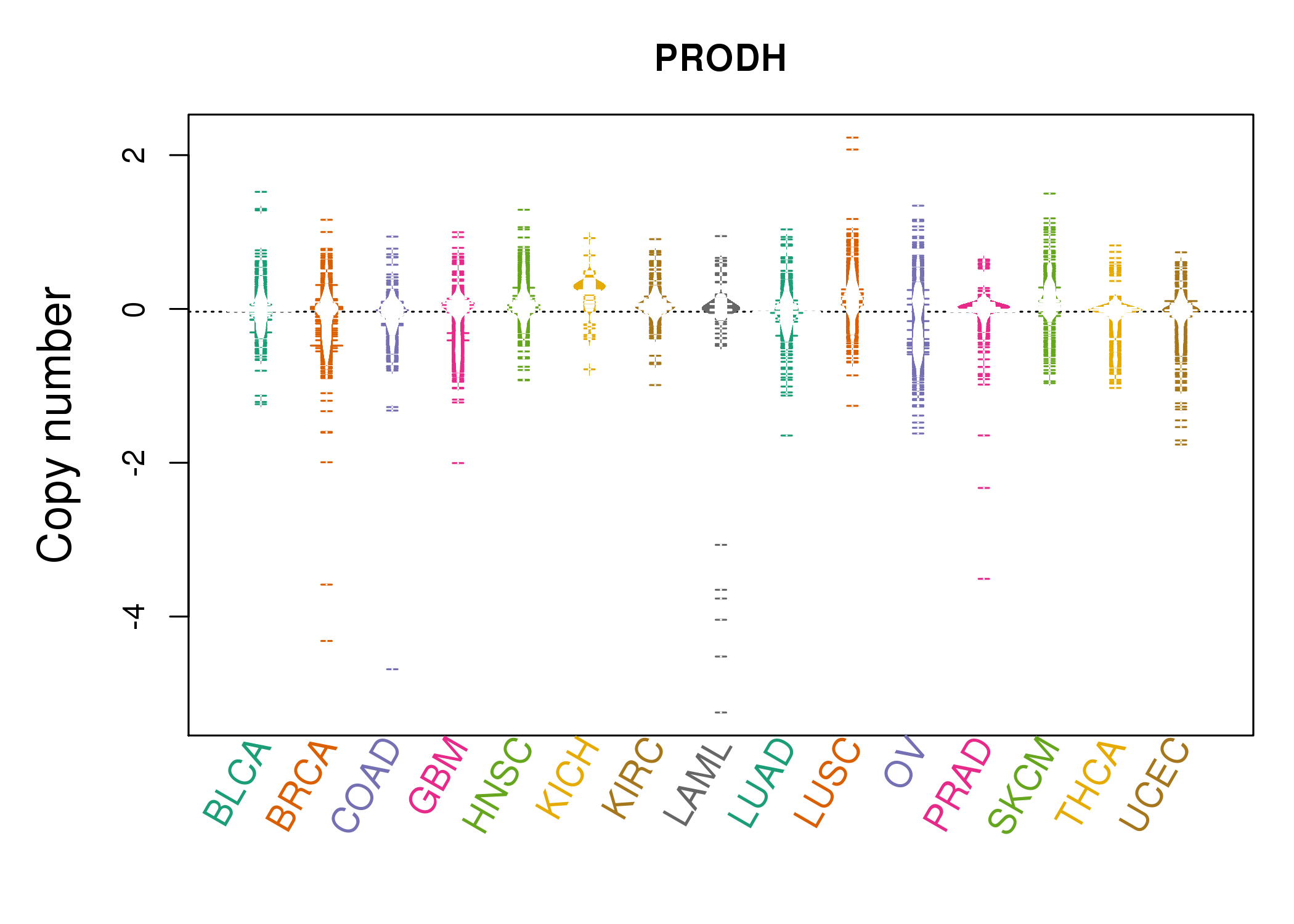 |
| cf) Tissue ID[Tissue type]: BLCA[Bladder Urothelial Carcinoma], BRCA[Breast invasive carcinoma], CESC[Cervical squamous cell carcinoma and endocervical adenocarcinoma], COAD[Colon adenocarcinoma], GBM[Glioblastoma multiforme], Glioma Low Grade, HNSC[Head and Neck squamous cell carcinoma], KICH[Kidney Chromophobe], KIRC[Kidney renal clear cell carcinoma], KIRP[Kidney renal papillary cell carcinoma], LAML[Acute Myeloid Leukemia], LUAD[Lung adenocarcinoma], LUSC[Lung squamous cell carcinoma], OV[Ovarian serous cystadenocarcinoma ], PAAD[Pancreatic adenocarcinoma], PRAD[Prostate adenocarcinoma], SKCM[Skin Cutaneous Melanoma], STAD[Stomach adenocarcinoma], THCA[Thyroid carcinoma], UCEC[Uterine Corpus Endometrial Carcinoma] |
| Top |
| Gene Expression for PRODH |
| * CCLE gene expression data were extracted from CCLE_Expression_Entrez_2012-10-18.res: Gene-centric RMA-normalized mRNA expression data. |
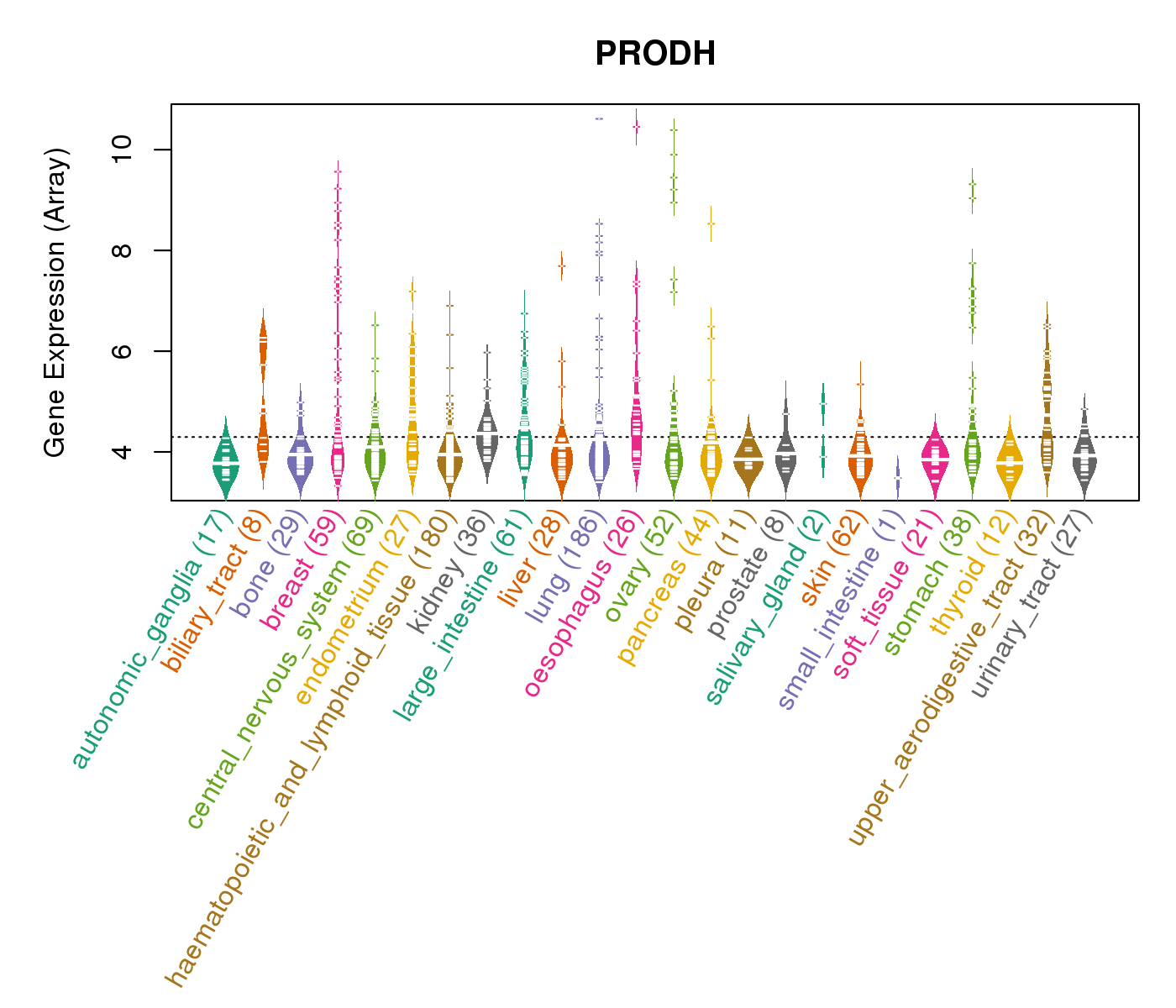 |
| * Normalized gene expression data of RNASeqV2 was extracted from TCGA using R package TCGA-Assembler. The URLs of all public data files on TCGA DCC data server were gathered at Jan-05-2015. Only eight cancer types have enough normal control samples for differential expression analysis. (t test, adjusted p<0.05 (using Benjamini-Hochberg FDR)) |
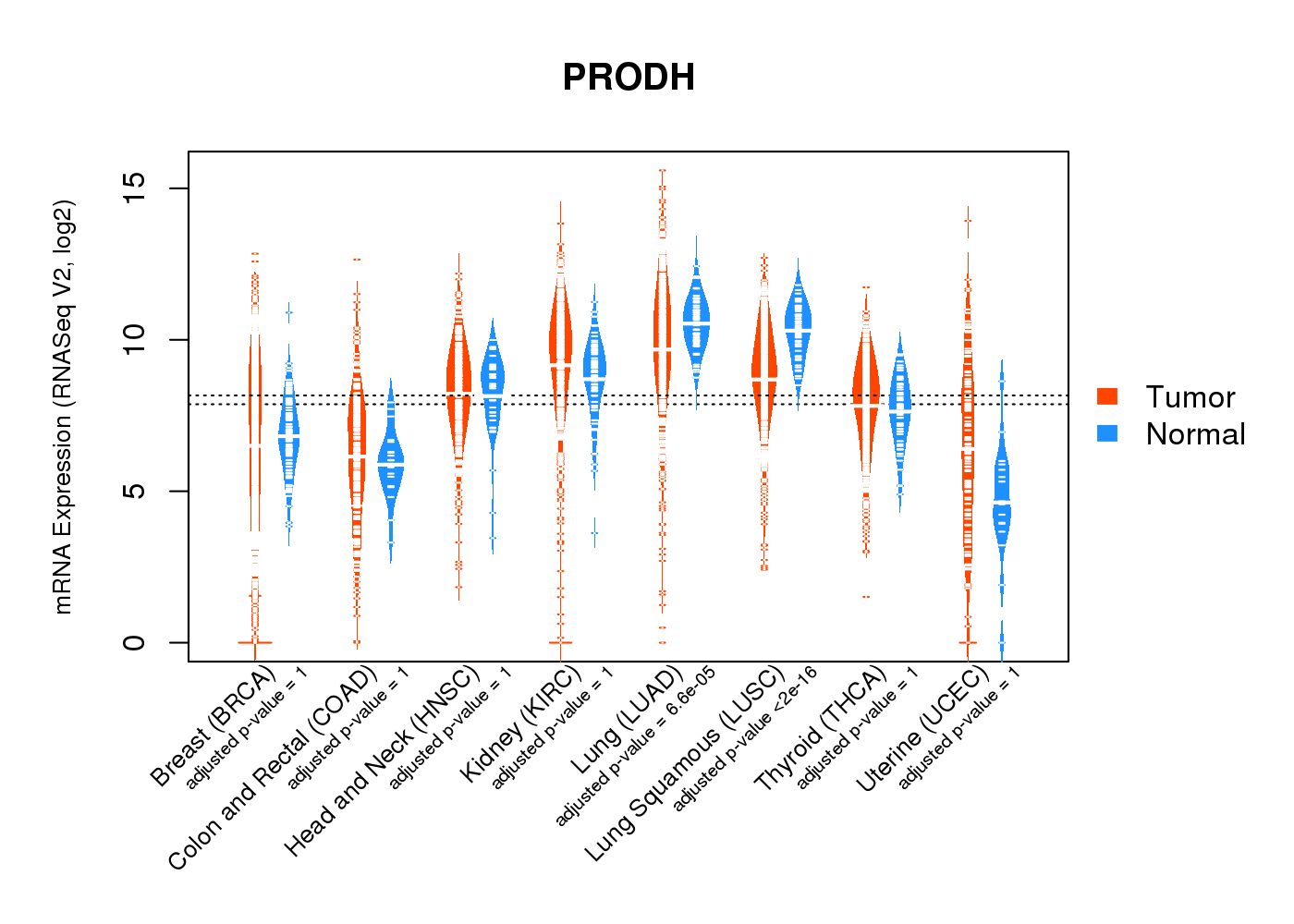 |
| Top |
| * This plots show the correlation between CNV and gene expression. |
: Open all plots for all cancer types
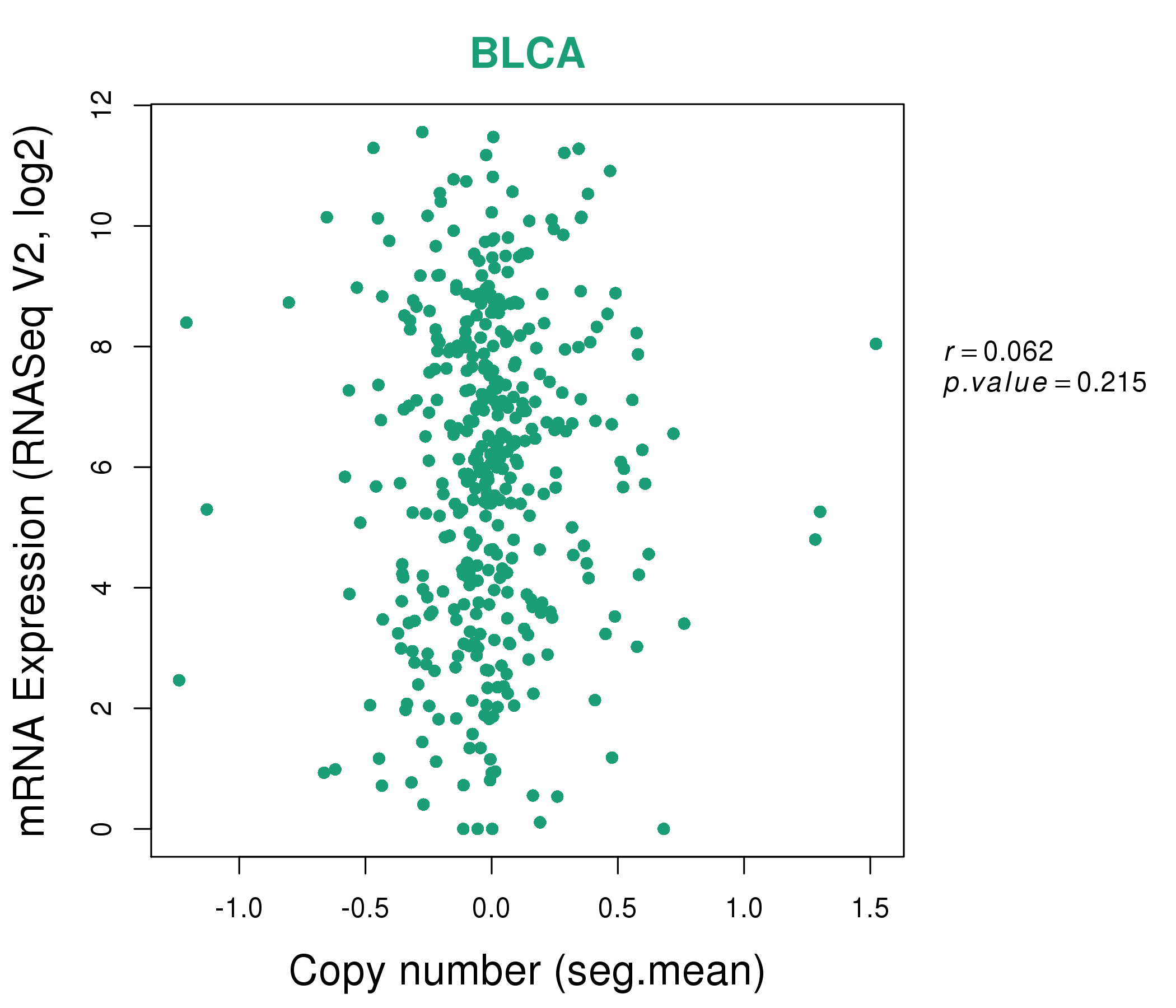 |
|
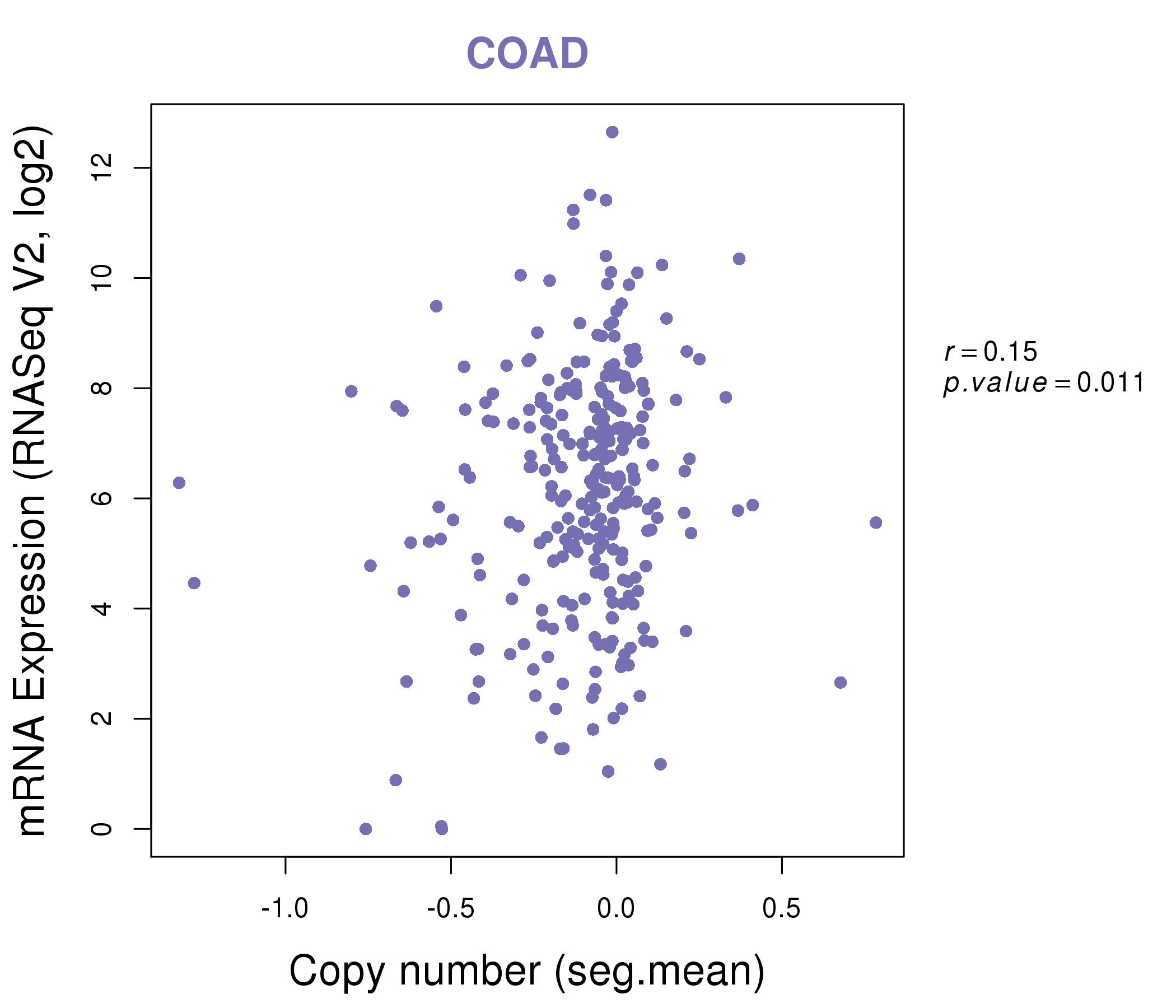 |
|
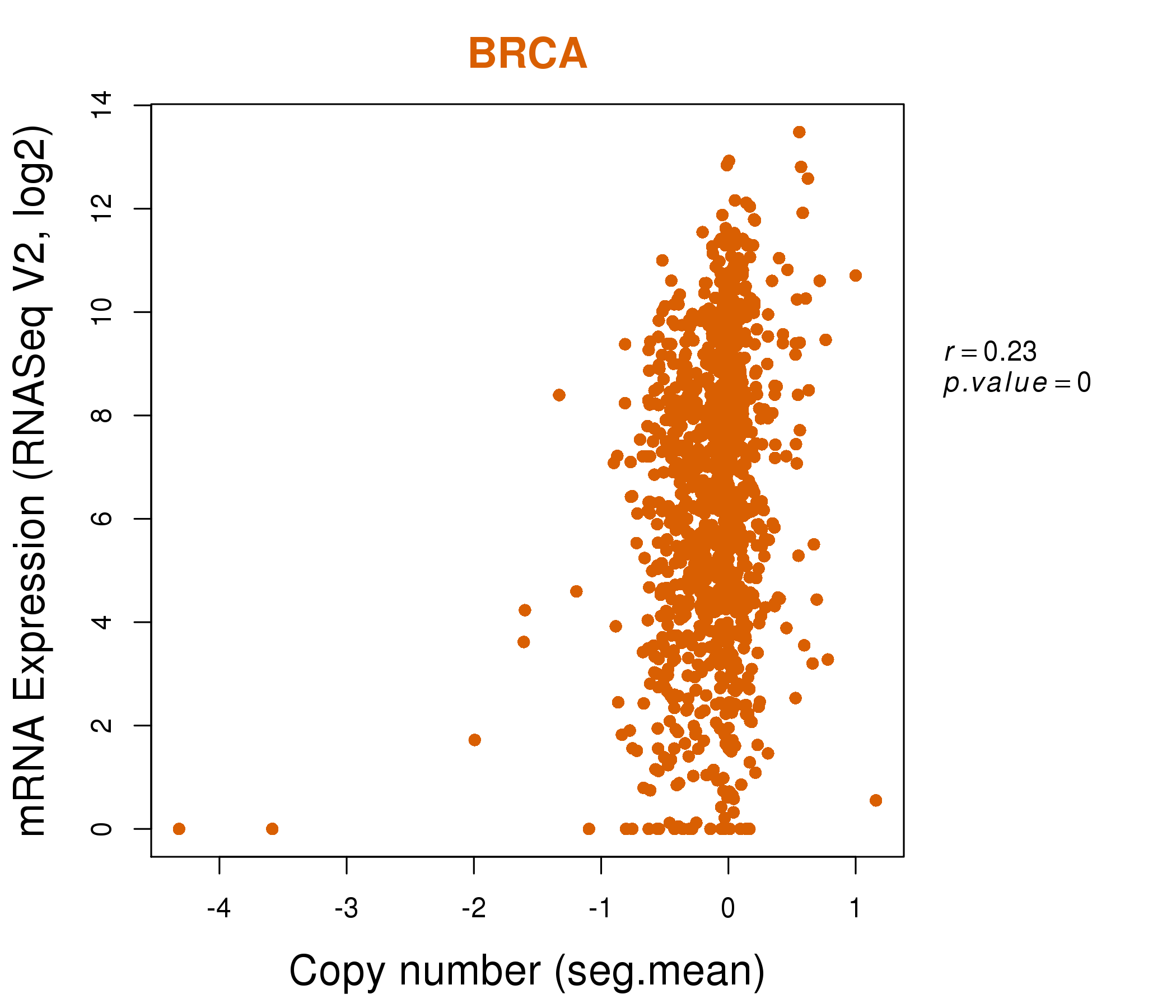
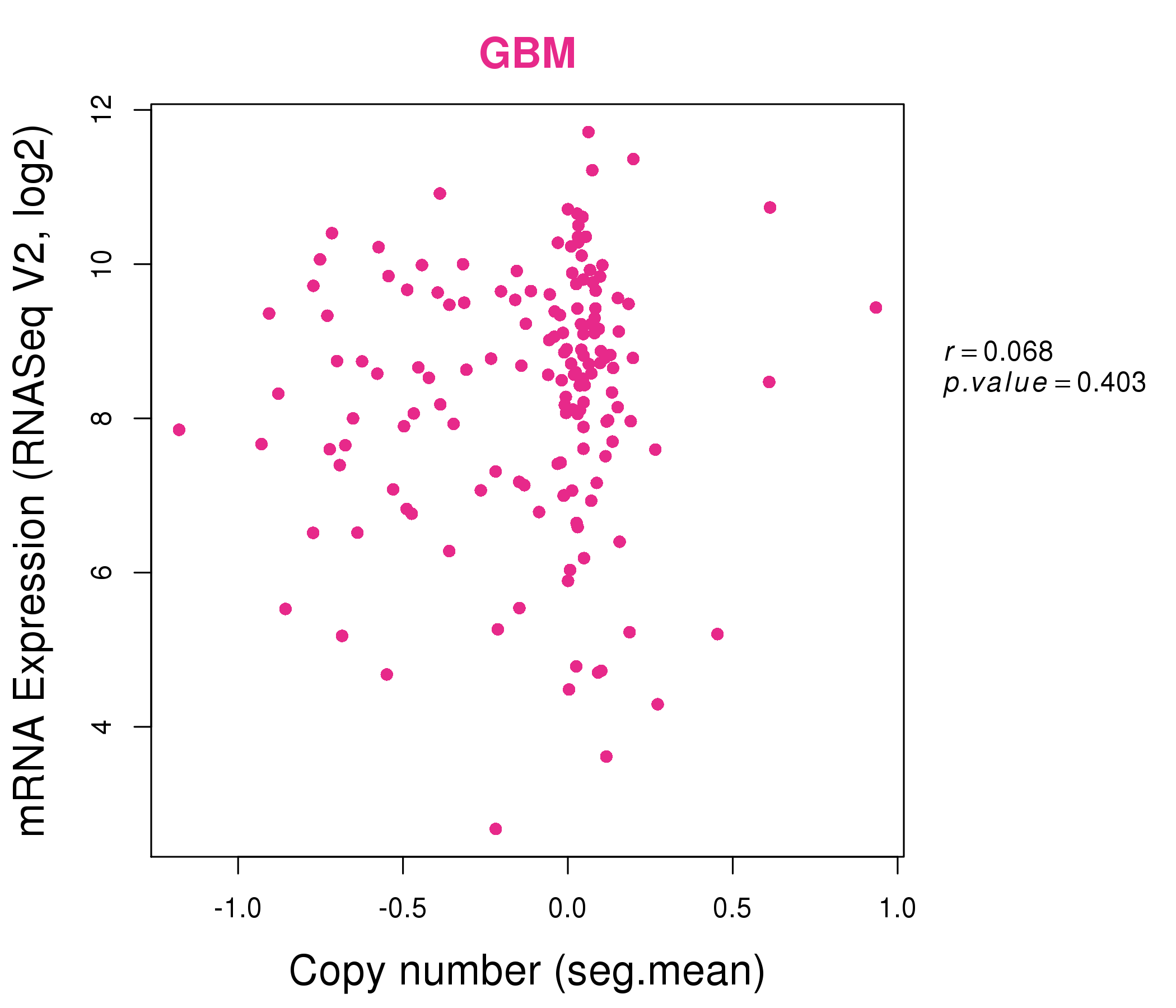
| Top |
| Gene-Gene Network Information |
| * Co-Expression network figures were drawn using R package igraph. Only the top 20 genes with the highest correlations were shown. Red circle: input gene, orange circle: cell metabolism gene, sky circle: other gene |
: Open all plots for all cancer types
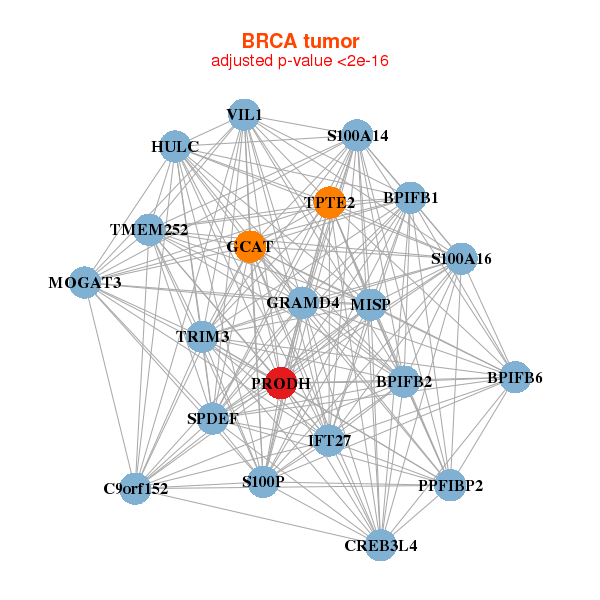 |
| ||||
| APCS,APOA2,APOA4,APOC3,C8A,C9,CREB3L3, CRP,F2,FABP1,FGF23,HP,ITIH1,MT1B, PLG,PRODH2,SERPINA7,SERPINC1,SLC17A2,SULT2A1,TM4SF5 | NA,NA,NA,NA,NA,NA,NA, NA,NA,NA,NA,NA,NA,NA, NA,NA,NA,NA,NA,NA,NA | ||||
 |
| ||||
| ARMC3,ATP6V1B1,LRRC71,CDC20B,FOXN4,GH2,HAPLN4, KCNH3,KCNJ16,KCNJ4,KCNQ2,KIF1A,LHFPL5,LPPR3, MOS,NECAB2,PAX4,PRODH2,RD3,TEKT1,TMEM190 | NPSR1-AS1,AQP5,C1orf146,C4orf51,C5orf47,GGNBP1,LHX3, LOC285627,MSH4,PDCL2,PRODH2,SERPINB7,SNORA71A,SNORA80A, SNORD15B,SPRR1A,SPRR1B,SYCP2L,CATSPERD,TRIM69,ZNF705A |

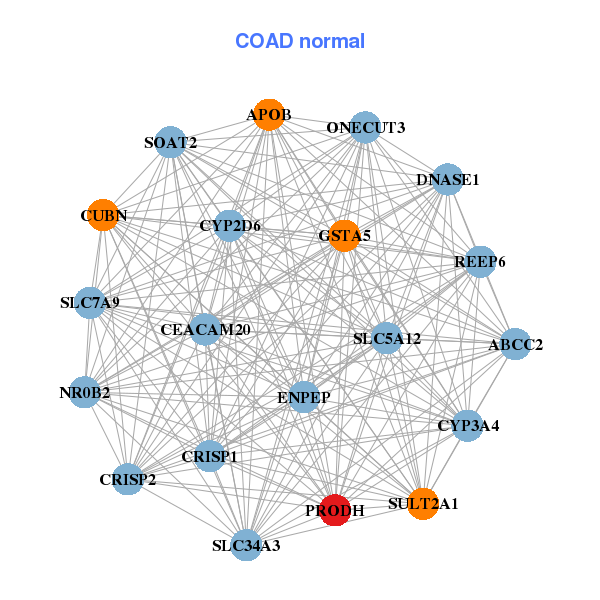
| * Co-Expression network figures were drawn using R package igraph. Only the top 20 genes with the highest correlations were shown. Red circle: input gene, orange circle: cell metabolism gene, sky circle: other gene |
: Open all plots for all cancer types
| Top |
: Open all interacting genes' information including KEGG pathway for all interacting genes from DAVID
| Top |
| Pharmacological Information for PRODH |
| DB Category | DB Name | DB's ID and Url link |
| Organism-specific databases | PharmGKB | PA33801; -. |
| Organism-specific databases | PharmGKB | PA33801; -. |
| Organism-specific databases | CTD | 5625; -. |
| Organism-specific databases | CTD | 5625; -. |
| * Gene Centered Interaction Network. |
 |
| * Drug Centered Interaction Network. |
| DrugBank ID | Target Name | Drug Groups | Generic Name | Drug Centered Network | Drug Structure |
| DB00172 | proline dehydrogenase (oxidase) 1 | approved; nutraceutical | L-Proline | 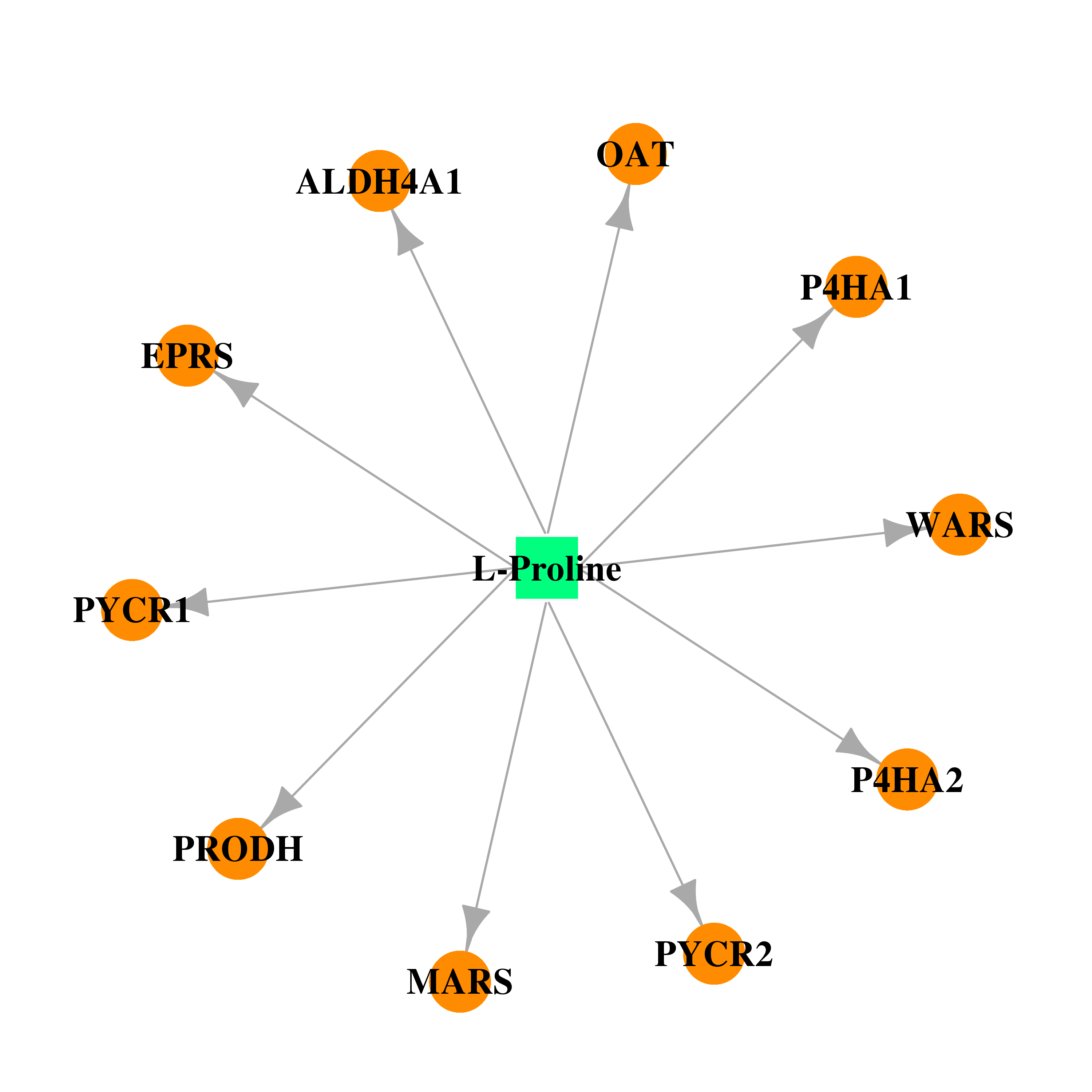 | 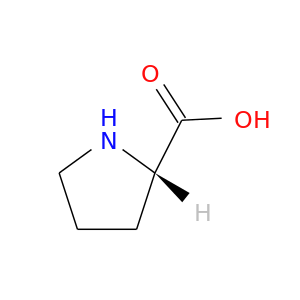 |
| Top |
| Cross referenced IDs for PRODH |
| * We obtained these cross-references from Uniprot database. It covers 150 different DBs, 18 categories. http://www.uniprot.org/help/cross_references_section |
: Open all cross reference information
|
Copyright © 2016-Present - The Univsersity of Texas Health Science Center at Houston @ |